
Optical Character Recognision ಅಂದರೆ ಏನು? ಚಿತ್ರದಲ್ಲಿ ಇರುವ ಅಕ್ಷರಗಳನ್ನು ಗುರುತಿಸಿ, ಅವುಗಳನ್ನು ನಿಜವಾದ ಅಕ್ಷರಗಳಂತೆ ಬದಲಾಯಿಸುವುದು. ನಿಜವಾದ ಅಕ್ಷರಗಳಿದ್ದರೆ, ಅವುಗಳಿಂದ ಬೇಕಾದ ಪದಗಳನ್ನಷ್ಟೇ ಕತ್ತರಿಸಬಹುದು, ಬಣ್ಣ ಬದಲಾಯಿಸಬಹುದು ಹಾಗೂ ಕೆಲವು ಪದ/ವಾಕ್ಯಗಳನ್ನಷ್ಟೇ ಬದಲಾಯಿಸಬಹುದು. ಅದೇ ಚಿತ್ರದ ರೂಪದಲ್ಲಿದ್ದರೆ ಇದು ಸಾಧ್ಯವಿಲ್ಲ, ಎಲ್ಲವನ್ನೂ ಪುನಃ ಬರೆಯಬೇಕಾಗುತ್ತದೆ.
OCR ಈಗಾಗಲೇ ಇಂಗ್ಲಿಷ್ ಭಾಷೆಗೆ ಇದ್ದರೆ, ಕನ್ನಡಕ್ಕೆ ಏಕಿಲ್ಲ, ಅದನ್ನು ಮಾಡಬಹುದೇ? ಈ ಲೇಖನದ ಮೂಲಕ OCR ಕೆಲಸ ಮಾಡುವ ಬಗೆ ಮತ್ತು ಈಗಿರುವ ತೊಂದರೆಗಳ ಬಗ್ಗೆ ತಿಳಿದುಕೊಳ್ಳೋಣ.
ಈ ತಂತ್ರಾಂಶವು ಮೊದಲಿಗೆ ಚಿತ್ರದಲ್ಲಿ ಇರುವ ಕಪ್ಪು ಬಿಳುಪಿನ ಬಣ್ಣಗಳ ಬದಲಾವಣೆಗಳ ಮೂಲಕ ಆ ಚಿತ್ರವನ್ನು ಸಣ್ಣ ಸಣ್ಣ ಭಾಗಗಳನ್ನಾಗಿ ವಿಂಗಡಿಸುತ್ತದೆ. ಮೊದಲಿಗೆ ಉದ್ದನೆಯ ಬಿಳಿಯ ಅಥವಾ ಖಾಲಿ ಜಾಗವನ್ನು ಗುರುತಿಸಿ ಒಂದೊಂದು ಸಾಲುಗಳು ಎಂದು ಭಾಗ ಮಾಡುತ್ತೆ, ನಂತರ ಪ್ರತೀ ಸಾಲಿನಲ್ಲೂ ಮದ್ಯದ ಖಾಲಿ ಜಾಗವನ್ನು ಗುರುತಿಸಿ ಒಂದೊಂದು ಅಕ್ಷರಗಳೆಂದು ವಿಭಾಗಿಸುತ್ತೆ. ಆ ನಂತರ ತನ್ನಲ್ಲಿ ಇರುವ ಮಾಹಿತಿಯ ಪ್ರಕಾರ ಭಾಗ ಮಾಡಿದ ಪ್ರತಿಯೊಂದು ಸಣ್ಣ ಭಾಗವನ್ನೂ ಇಂತದ್ದೇ ಅಕ್ಷರವೆಂದು ಗುರುತಿಸುತ್ತದೆ.
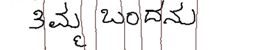
ಚಿತ್ರದಲ್ಲಿರುವ ಗೆರೆಗಳು ತಂತ್ರಾಂಶವು ಚಿತ್ರವನ್ನು ಹೇಗೆ ವಿಭಾಗಿಸುತ್ತದೆ ಎಂಬುದನ್ನ ತೋರಿಸುತ್ತದೆ.
ಅಕ್ಷರಗಳನ್ನು ಗುರುತಿಸಲು ತನ್ನಲ್ಲಿರೋ ಮಾಹಿತಿ ಉಪಯೋಗಿಸುತ್ತೆ ಎಂದು ತಿಳೀತು, ಆದರೆ ಈ ಮಾಹಿತಿ ಅದಕ್ಕೆ ಎಲ್ಲಿಂದಾ ಸಿಗುತ್ತೆ? ಅದಕ್ಕೋಸ್ಕರವೇ ಮೊದಲಿಗೆ OCR ತಂತ್ರಾಂಶಕ್ಕೆ ತರಬೇತಿ ಕೊಡಬೇಕಾಗುತ್ತೆ. ತರಬೇತಿ ಅಂದರೆ ವರ್ಣಮಾಲೆಯಲ್ಲಿರುವ ಪ್ರತೀ ಅಕ್ಷರಗಳನ್ನು ಯಾವ ಯಾವ ರೀತಿ ಬರೆಯಬಹುದು ಎಂದು ತಿಳಿಸಿಕೊಡೋದು. ಈ ತರಬೇತಿ ಹೆಚ್ಚು ಫಾಂಟ್ ಗಳಿಗೆ ಮಾಡಿದಷ್ಟೂ OCR ಚೆನ್ನಾಗಿ ಕೆಲಸ ಮಾಡುತ್ತದೆ.
ಒಂದೊಂದೇ ಅಕ್ಷರಗಳನ್ನು ಯಾಕೆ ಗುರುತಿಸಬೇಕು? ಒಟ್ಟಿಗೇ ಒಂದಷ್ಟು ಪದಗಳನ್ನು ಗುರುತಿಸಬಹುದಲ್ವಾ ಎಂಬ ಪ್ರಶ್ನೆ ನಿಮಗೀಗ ಬಂದಿರಬಹುದು. ಪದಗಳನ್ನು ಒಟ್ಟಿಗೇ ಮಾಡುವುದಾದರೆ combination ಬಹಳ ಆಗಿ ತಂತ್ರಾಂಶ ಕೆಲಸ ಮಾಡುವುದೇ ಕಷ್ಟ ಆಗುತ್ತದೆ. ಉದಾಹರಣೆ ಇಂಗ್ಲಿಷ್ ನಲ್ಲಿ a b c d ಎಂಬ ನಾಲ್ಕು ಅಕ್ಷರಗಳನ್ನೇ ಬಹಳಷ್ಟು ತರಹದಲ್ಲಿ ಬರೆಯಬಹುದು. ಉದಾಹರಣೆಗೆ abcd, abdc, adbc, dabc, acbd… ಹಾಗಾಗಿ ಅಕ್ಷರಗಳ ಬದಲಿಗೆ ಪದಗಳನ್ನು ಕೊಟ್ಟರೆ OCR ಗೆ ತರಬೇತಿ ಕೊಡುವುದು ಕಬ್ಬಿಣದ ಕಡಲೆ ಆಗುತ್ತದೆ.
ಕನ್ನಡಕ್ಕೆ OCR ಮಾಡಲು ಈಗಿರುವ ತೊಂದರೆಗಳು
ಮೊದಲೇ ಹೇಳಿದಂತೆ, ಈ ತಂತ್ರಾಂಶವು ತನಗೆ ಕೊಟ್ಟ ಚಿತ್ರವನ್ನು ಮೇಲಿನಿಂದ ಕೆಳಗೆ ನೋಡಿ ಅದರಿಂದ ಸಾಲುಗಳಂತೆ ವಿಂಗಡಿಸಿ ನಂತರ ಎಡದಿಂದ ಬಲಕ್ಕೆ ನೋಡಲು ಪ್ರಾರಂಭಿಸುತ್ತೆ. ಚಿತ್ರದಲ್ಲಿನ ಕಪ್ಪು ಬಿಳುಪಿನ ಆಧಾರದ ಮೇಲೆ ಒಂದು ಸಾಲಿನಲ್ಲಿ ಸಣ್ಣ ಸಣ್ಣ ಭಾಗಗಳನ್ನು ಗುರುತಿಸುತ್ತದೆ. ಈ ಸಂದರ್ಭದಲ್ಲಿ ಕನ್ನಡದ ಒಂದೇ ಅಕ್ಷರವನ್ನು ಎರಡು ಭಾಗ ಮಾಡುವ ಸಾಧ್ಯತೆ ಇದೆ. ಇದಕ್ಕೆ ಮುಖ್ಯ ಕಾರಣ ಆ ಅಕ್ಷರದ ಎರಡು ಭಾಗಗಳು ಕೂಡದೇ ಇರುವುದು. ಕೆಳಗಿನ ಉದಾಹರಣೆಯಲ್ಲಿ ತೋರಿಸಿದಂತೆ “ಕೀ” ಅಕ್ಷರವನ್ನು ಎರಡು ಭಾಗ ಮಾಡುತ್ತದೆ, ತರಬೇತಿ ಮಾಡುವಾಗ ಕೊಟ್ಟ ಮಾಹಿತಿಯಲ್ಲಿ “ಕಿ” ಗುರುತಿಸುವ ಬಗ್ಗೆ ಇದೆ ಆದರೆ ಬರೀ ಧೀರ್ಘ ಬಂದಾಗ ಏನು ಮಾಡುವುದು ಎಂದು ಆ ತಂತ್ರಾಂಶಕ್ಕೆ ಹೇಳುವುದು ಕಷ್ಟ. ಇಂಗ್ಲಿಷ್ ನಲ್ಲಾದರೆ ಒಂದೊಂದು ಅಕ್ಷರವೂ ಸ್ವತಂತ್ರ. ಎರಡು ಅಕ್ಷರಗಳು ಸೇರಿಸಿದಾಗ ಇನ್ನೇನೋ ಅಕ್ಷರ ಆಗುವ ಸಂಭವ ಇಲ್ಲ. ಇದ್ದರೂ ಬಹಳ ಕಡಿಮೆ. ಮುಂಚೆ ಹೇಳಿದ “ಕೀ” ತೊಂದರೆಗೆ “ಕಿ” ಮತ್ತು ಧೀರ್ಘಕ್ಕೆ ಬೇರೆ ಬೇರೆ ಮಾಹಿತಿ ಕೊಟ್ಟರೂ ಕೊನೆಯಲ್ಲಿ ಜೋಡಿಸುವಾಗ ಯುನಿಕೋಡ್ ನ ಪ್ರಕಾರ ಅವೆರಡು ಜೋಡುವುದಿಲ್ಲ.

ಮೇಲಿನ ತೊಂದರೆಗೆ ಒಂದು ತಾತ್ಕಾಲಿಕ ಪರಿಹಾರ ಹುಡುಕಿಕೊಂಡಿದ್ದೇವೆ, ಆದರೆ ಬಹುಮುಖ್ಯ ಸಮಸ್ಯೆ ಒತ್ತಕ್ಷರಗಳದ್ದು. ಒತ್ತಕ್ಷರಗಳನ್ನು ಮುಖ್ಯ ಅಕ್ಷರಗಳಿಂದ ಬೇರೆಯಾಗಿ ಗುರುತಿಸೋದು ಕಷ್ಟ. ಒಂದೊಂದು ಫಾಂಟ್ ನಲ್ಲಿ ಒಂದೊಂದು ತರಹವಿರುತ್ತದೆ, ಕೆಳಗಿನ ಉದಾಹರಣೆಗಳನ್ನು ನೋಡಿ, ಎರಡನೆಯ ಚಿತ್ರದಲ್ಲಿ ಒತ್ತಕ್ಷರ ಹಾಗೂ ಮುಖ್ಯ ಅಕ್ಷರವನ್ನು ಒಂದು ಗೆರೆ ಹಾಕಿ ಬೇರೆ ಬೇರೆಯಾಗಿ ಗುರುತಿಸಬಹುದು. ಆದರೆ ಕೆಲವು ಫಾಂಟ್ ಗಳಲ್ಲಿ ಬರೆದಿದ್ದನ್ನು ಬೇರೆ ಬೇರೆಯಾಗಿ ಗುರುತಿಸಲು ಆಗುವುದಿಲ್ಲ(ಮೊದಲನೇ ಚಿತ್ರ ನೋಡಿ), ಅವೆರಡನ್ನೂ ಒಂದೇ ಅಕ್ಷರವಾಗಿ ಗುರುತಿಸಿದರೆ ಮೇಲೆ ವಿವರಿಸಿದಂತೆ ಬಹಳಷ್ಟು combination ಗಳು ಆಗುತ್ತದೆ, ಉದಾ: ಕ್ಗ, ಕ್ಗಿ, ಕ್ಗು, ಕ್ಗೂ… ಒತ್ತಕ್ಷರಗಳ combination ಗಳ ಸಂಖ್ಯೆ ಊಹಿಸಲೂ ಕಷ್ಟವಾಗುವಷ್ಟಾಗುತ್ತದೆ, ಇನ್ನು ಒಂದಕ್ಕಿಂತಾ ಜಾಸ್ತಿ ಒತ್ತು ಬರುವ ಪದಗಳನ್ನು ಊಹಿಸಿಕೊಳ್ಳಿ.
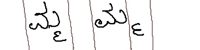
ಇದುವರೆಗೆ ಬರೆದ ವಿಚಾರಗಳು Tesseract OCR ಎಂಬ ತಂತ್ರಾಂಶವನ್ನು ಗೆಳೆಯರ ಜೊತೆ ಸೇರಿ ಕನ್ನಡಕ್ಕೆ ಅಳವಡಿಸಲು ಪ್ರಯತ್ನ ಮಾಡಿದಾಗಿನ ಅನುಭವ. ಇನ್ನೂ ಬಹಳಷ್ಟು ತೊಂದರೆಗಳಿಗೆ ಪರಿಹಾರ ಸಿಕ್ಕಿಲ್ಲ. ಎಲ್ಲಾ ತೊಂದರೆಗಳು ಒಂದೊಂದಾಗಿ ಸರಿಯಾಗಿ ಕಡೆಗೊಂದಿನ ಕನ್ನಡಕ್ಕೂ ಒಂದು OCR ಬರಲಿ ಎಂದು ಆಶಿಸುತ್ತೇನೆ.
